Custom Audiences
Overview
There are multiple ways for partners to create Custom Audiences.
Please note that you cannot exclude lookalike custom audiences from targeting. Additionally, you cannot target both a custom audience and a custom audience lookalike on the same ad line item (ad group).
Audience management
Audiences can be managed via audience partners and Ads API partners. We offer a series of endpoints in the API to access and maintain custom audiences.
For custom audience information, we offer 2 endpoints:
- GET accounts/:account_id/custom_audiences
- GET accounts/:account_id/custom_audiences/:custom_audience_id
For more details on how to upload and manage audiences, view the Audience API guide.
Processing Times
Generally speaking audience changes are processed in batches that run every 6-8 hours. While an audience change is processing the existing audience to be updated is unaffected. We do not recommend making more than one update for additions and one update for removals per audience within this timeframe.
Targeting
An audience can only be targeted if it matches at least 100 users active within the past 90 days on Twitter-owned and -operated clients. GET accounts/:account_id/custom_audiences/:custom_audience_id will indicate if an audience may not be targeted because it matches too few users.
Audience API (CRM)

Audience or API partners provide a list of hashed identifiers and Twitter performs a match and produces segments that are made available against media buying on Twitter. Partners can create these audiences with the Audience API.
How it works?

Web
We offer a standard cookie matching process when working with MPP audience partners to identify segments to target against media buying on Twitter. In addition, advertsiers can setup a Twitter Web Event Tag to collect website user data and create a corresponding Custom Audience.
Setup Steps
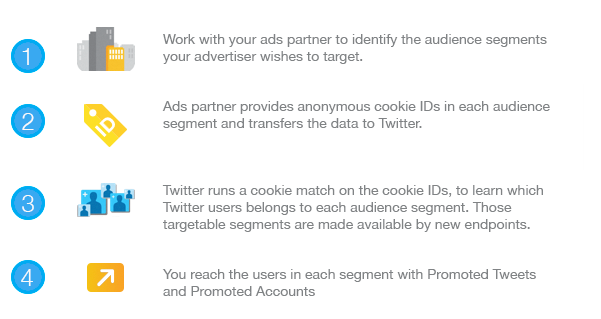
How it works?

Flexible
Flexible audiences give advertisers the ability to build and save audience combinations based on existing custom audiences or subsets of existing custom audiences. Subsets of a custom audience’s members can be targeted based on the recency and frequency of interaction.